目标:把 RL 的直觉翻译成严格的数学语言。本章是全书最重要的基础,后面每个算法都是在 MDP 框架上建立的。
3.1 MDP 的正式定义
马尔可夫决策过程(Markov Decision Process)是描述序列决策问题的标准数学框架,用五元组定义:
\[\mathcal{M} = (\mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R}, \gamma)\]| 符号 | 名称 | 说明 |
|---|---|---|
| $\mathcal{S}$ | 状态空间 | 所有可能状态的集合 |
| $\mathcal{A}$ | 动作空间 | 所有可能动作的集合 |
| $\mathcal{P}$ | 状态转移函数 | $\mathcal{P}(s’\vert s,a)=P(s_{t+1}=s’\vert s_t=s,a_t=a)$ |
| $\mathcal{R}$ | 奖励函数 | $\mathcal{R}(s,a,s’)$:执行动作后获得的奖励 |
| $\gamma$ | 折扣因子 | $\gamma \in [0,1)$,控制对未来奖励的重视程度 |
具体例子——机器人行走的 MDP:
S: 关节角度 θ₁...θ₁₂ + 角速度 ω₁...ω₁₂ + IMU姿态 + 脚接触信号
(维度:通常 40-60 维连续向量)
A: 各关节目标力矩 τ₁...τ₁₂
(维度:12 维连续向量,值域通常 [-1, 1] 归一化)
P: 仿真物理引擎(MuJoCo/IsaacGym)或真实世界动力学
(通常未知,不可显式访问)
R: 前进速度 - 摔倒惩罚 - 能量消耗 - 姿态偏差
γ: 通常取 0.99
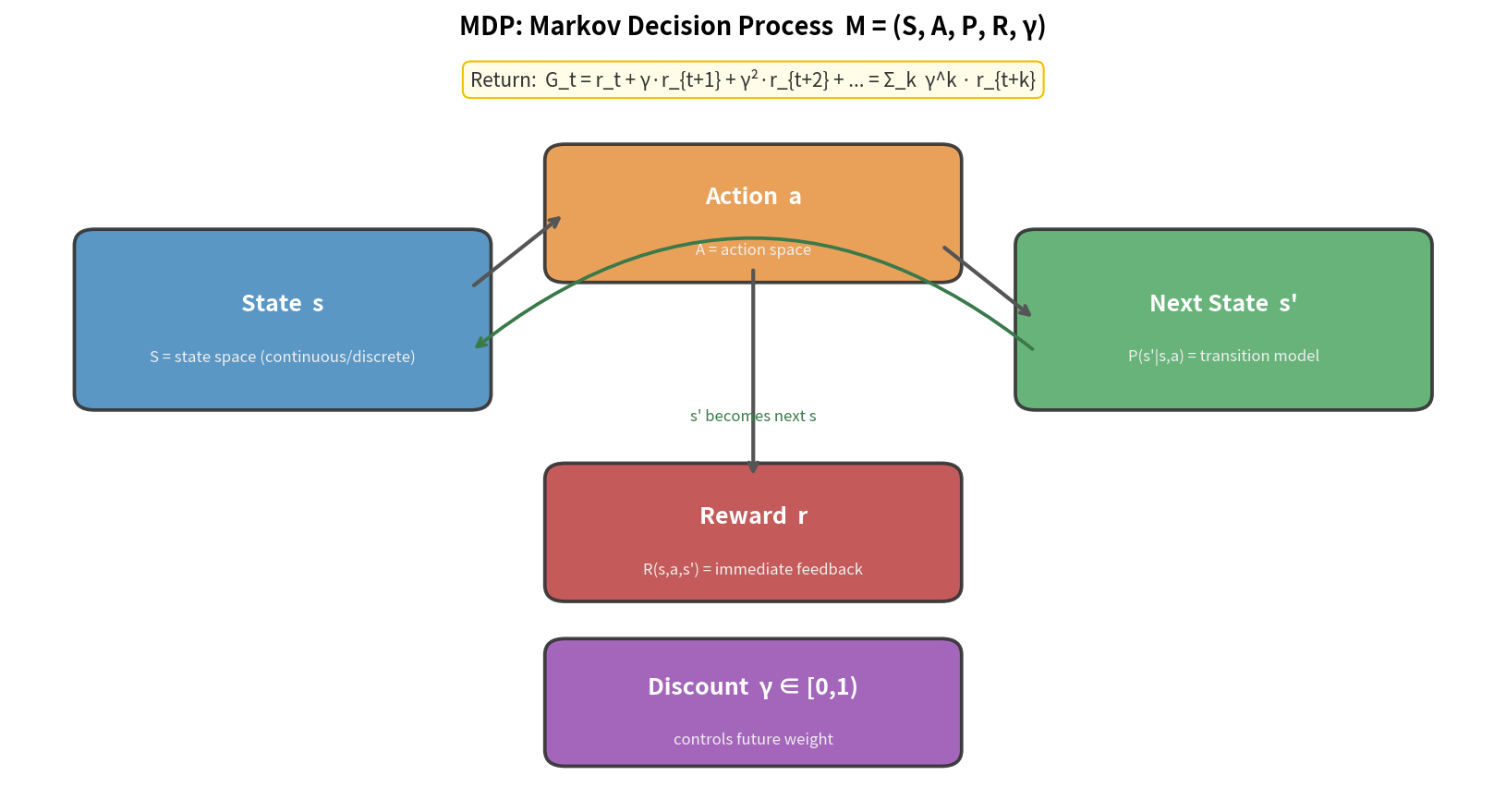
3.2 状态转移函数
状态转移函数 $\mathcal{P}(s’ \vert s,a)$ 描述了在状态 $s$ 执行动作 $a$ 后,转移到状态 $s’$ 的概率。
动作 a
当前状态 s ──────────────────► 下一状态 s'
P(s'|s,a)
确定性环境:$\mathcal{P}(s’\vert s,a) = 1$ 对某一个 $s’$ 成立,其余为 0。
随机性环境:同样的 $(s,a)$ 可能导致多种 $s’$,例如机器人脚踩到随机地形。
无模型 vs 有模型:
有模型 RL(Model-Based):知道 P(s'|s,a) → 可以规划
无模型 RL(Model-Free) :不知道 P(s'|s,a) → 只能采样交互
← 本书重点
3.3 折扣因子 γ 的直觉与数学意义
为什么需要折扣?
考虑一个无限长的任务(机器人持续行走),如果每步都有奖励,累积奖励会无限大——数学上没有意义。
折扣因子 $\gamma \in [0,1)$ 让未来的奖励打折,使得总回报有界:
\[G_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots = \sum_{k=0}^{\infty} \gamma^k r_{t+k}\]当 $\vert r_t \vert \leq r_{\max}$ 时,$G_t \leq \frac{r_{\max}}{1-\gamma}$(等比级数,有界)。
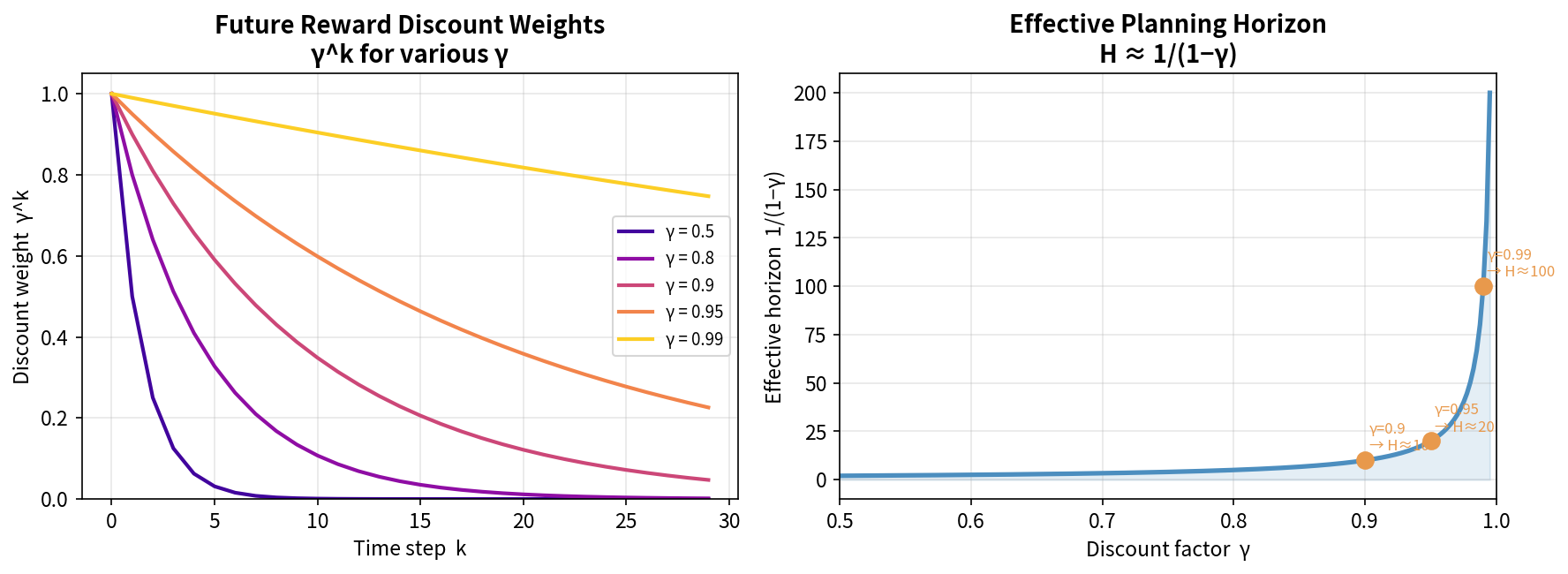
γ 的直觉意义
γ 的含义:距离现在 k 步的奖励,只值现在奖励的 γᵏ
γ = 0.99, k=100 步后的奖励 → 现在价值 0.99¹⁰⁰ ≈ 0.37
γ = 0.9, k=10 步后的奖励 → 现在价值 0.9¹⁰ ≈ 0.35
γ → 0 :只关心即时奖励(极度短视)
γ → 1 :同等重视所有未来奖励(极度有远见)
另一个解读:$\gamma$ 可以被理解为每一步以 $(1-\gamma)$ 的概率”游戏结束”——这给了它概率上的合理性。
γ 的工程经验
机器人行走任务:γ = 0.99(需要长期规划步态)
简单格子世界:γ = 0.9
游戏(短 Episode):γ = 0.99 ~ 0.999
3.4 回报(Return)
回报是从时刻 $t$ 开始的折扣累积奖励:
\[G_t = \sum_{k=0}^{T-t} \gamma^k r_{t+k} = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots\]关键递推关系(后面 Bellman 方程的起源):
\[\boxed{G_t = r_t + \gamma G_{t+1}}\]这个式子说明:当前的回报 = 即时奖励 + 折扣后的未来回报。
这是整个 RL 的核心递推结构,Bellman 方程就是它在期望意义下的展开。
G_t = r_t + γ·G_{t+1}
= r_t + γ·(r_{t+1} + γ·G_{t+2})
= r_t + γ·r_{t+1} + γ²·G_{t+2}
= ...
3.5 策略:Agent 的行为规则
策略 $\pi$ 是从状态到动作(分布)的映射,描述 Agent 的完整行为模式。
确定性策略
\[\pi: \mathcal{S} \rightarrow \mathcal{A}, \quad a = \pi(s)\]给定状态,总是执行同一个动作。DDPG、TD3 等算法学习确定性策略。
随机性策略
\[\pi: \mathcal{S} \rightarrow \Delta(\mathcal{A}), \quad a \sim \pi(\cdot|s)\]给定状态,输出动作的概率分布,然后采样。PPO、SAC 学习随机策略。
为什么需要随机策略?
- 探索:随机性本身就是探索机制
- 部分可观测环境:纯确定性策略可能陷入循环
- 理论上,随机策略包含确定性策略作为特例(当某个动作概率为1时)
连续动作的随机策略(机器人控制常用):
输出 Gaussian 分布的均值和方差:
\[\pi_\theta(a|s) = \mathcal{N}(\mu_\theta(s), \sigma_\theta^2(s))\]策略网络
输入: s (观测)
↓
隐藏层
↓
输出: μ(s) 和 log σ(s)
↓
采样: a ~ N(μ, σ²)
3.6 价值函数:长期回报的预估
价值函数回答的问题:从当前“状态”/“状态-动作对”出发,遵循策略 $\pi$,期望能获得多少累积奖励?
状态价值函数 $V^\pi(s)$
\[V^\pi(s) = \mathbb{E}_\pi[G_t | s_t = s] = \mathbb{E}_\pi\left[\sum_{k=0}^{\infty} \gamma^k r_{t+k} \bigg| s_t = s\right]\]直觉:站在状态 $s$,按策略 $\pi$ 行动,平均能拿到多少累积奖励。
动作价值函数 $Q^\pi(s, a)$
\[Q^\pi(s, a) = \mathbb{E}_\pi[G_t | s_t = s, a_t = a] = \mathbb{E}_\pi\left[\sum_{k=0}^{\infty} \gamma^k r_{t+k} \bigg| s_t = s, a_t = a\right]\]直觉:在状态 $s$,先执行动作 $a$,之后再按策略 $\pi$ 行动,平均能拿到多少累积奖励。
$V^\pi$ 与 $Q^\pi$ 的关系
\[V^\pi(s) = \sum_a \pi(a|s) Q^\pi(s, a) = \mathbb{E}_{a \sim \pi}[Q^\pi(s, a)]\]状态价值 = 按策略对动作价值的加权平均。
| 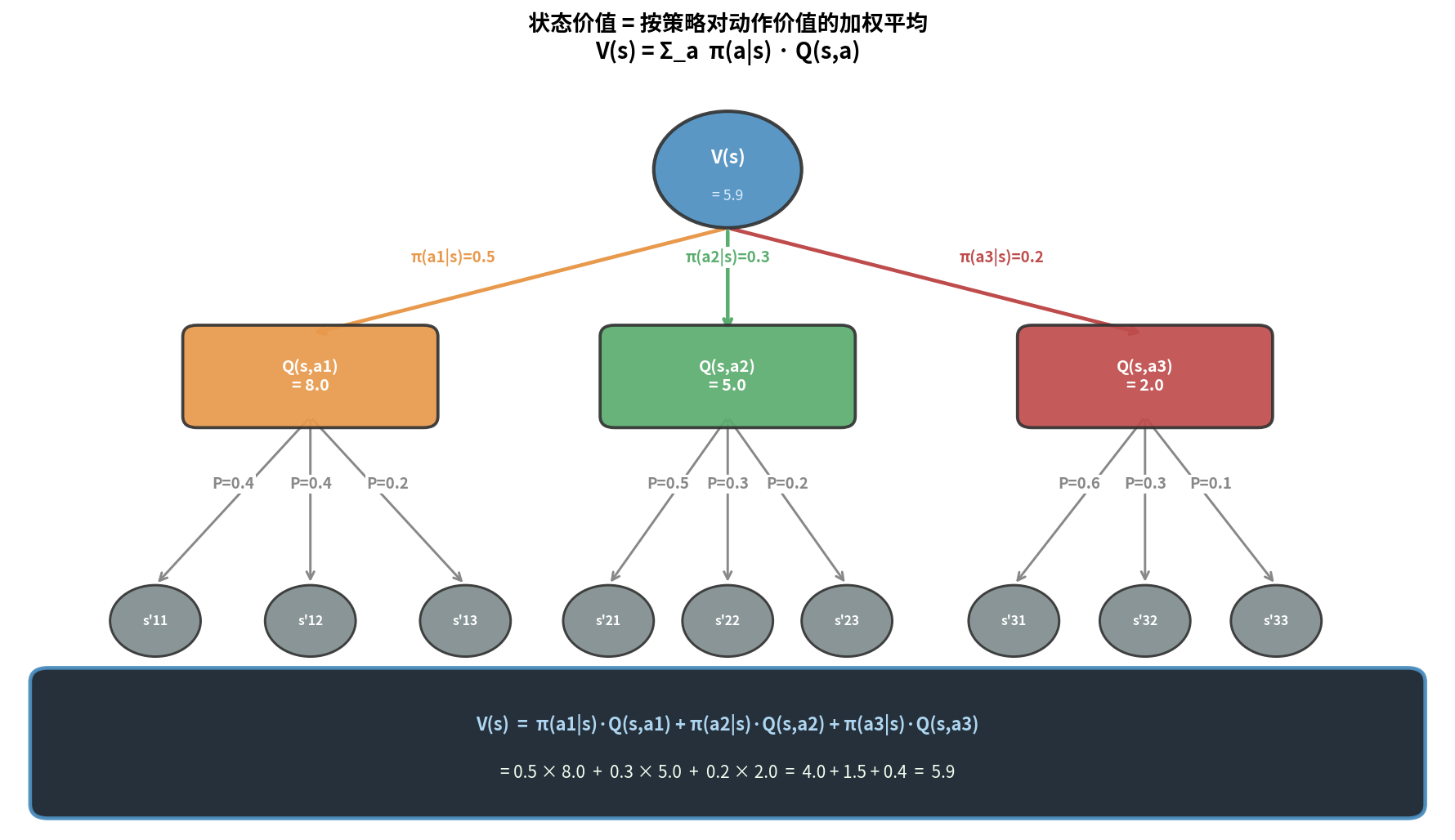 |
动作价值 = 即时奖励 + 折扣后的下一状态价值的期望。
┌──────────────┐
│ Q(s, a) │ 在状态 s 执行动作 a 的期望回报
└──────┬───────┘
│ 执行动作 a,环境随机转移
┌──────────┼──────────┐
│ │ │
P(s₁|s,a) P(s₂|s,a) P(s₃|s,a) 转移概率
│ │ │
V(s₁') V(s₂') V(s₃') 下一状态价值
│ │ │
(继续按π) (继续按π) (继续按π)
与上方 V→Q 图合在一起,形成完整的 Bellman 备份图:
V(s) ──[按策略选动作]──► Q(s,aᵢ) ──[环境转移]──► V(s')
↑ │
└──────────────────────────────────────────────────┘
一步 Bellman 递推
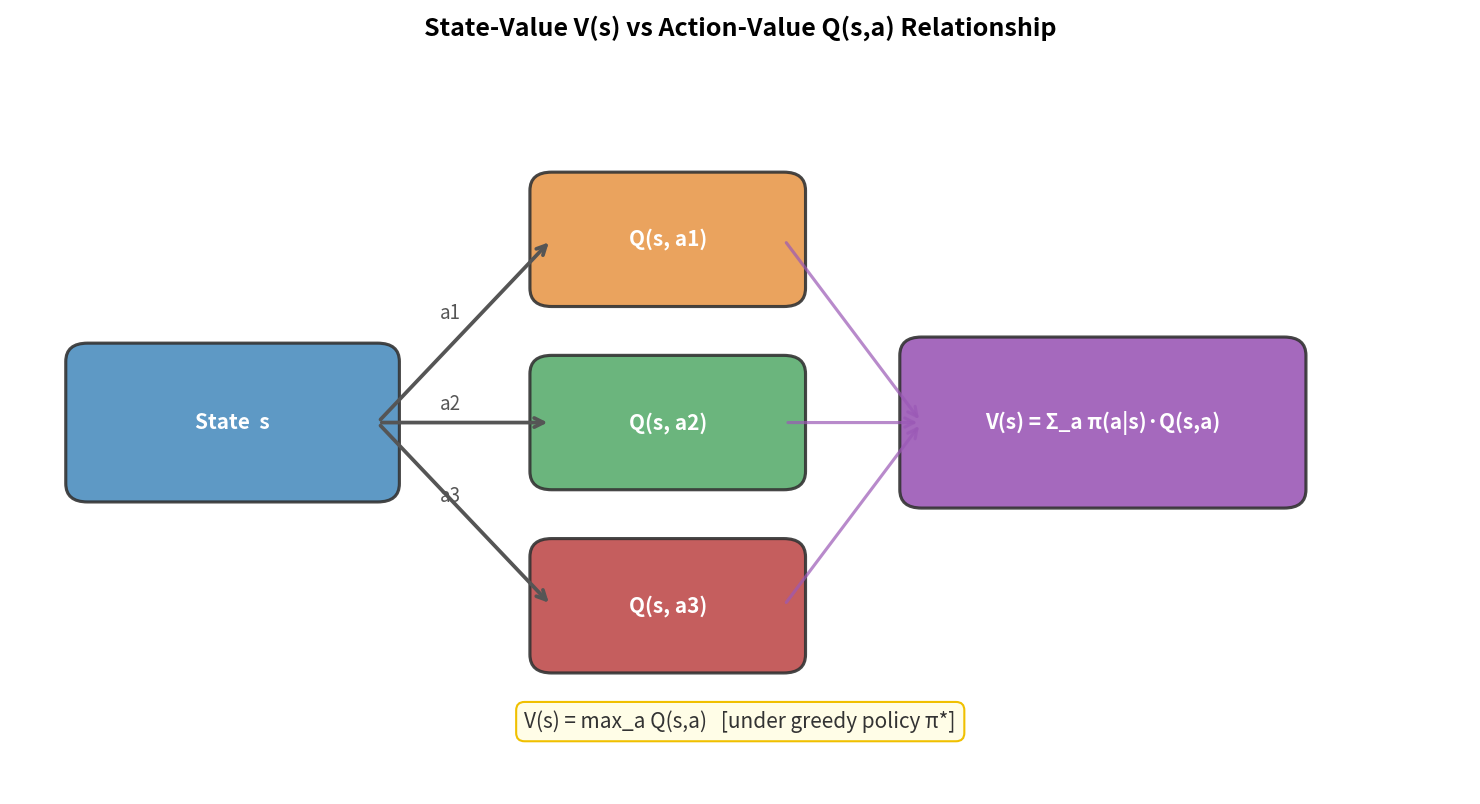
3.7 最优策略与最优价值函数
最优价值函数
\[V^*(s) = \max_\pi V^\pi(s) \quad \forall s \in \mathcal{S}\] \[Q^*(s, a) = \max_\pi Q^\pi(s, a) \quad \forall s \in \mathcal{S}, a \in \mathcal{A}\]最优策略
\[\pi^*(s) = \arg\max_a Q^*(s, a)\]重要定理:对任何 MDP,存在一个确定性最优策略 $\pi^*$,它同时最大化所有状态的价值。
两个价值函数的关系
\[V^*(s) = \max_a Q^*(s, a)\] \[Q^*(s, a) = \mathcal{R}(s,a) + \gamma \sum_{s'} \mathcal{P}(s'|s,a) V^*(s')\]3.8 部分可观测 MDP(POMDP)简介
真实机器人感知往往是不完整的,无法直接观测完整状态。
完整 MDP POMDP
─────────────────────────────────────────
Agent 知道完整状态 s Agent 只能看到观测 o
s 直接决定策略 需要从历史观测 o₁:t 推断状态
例:
MDP: 已知所有关节角度+角速度(完整状态)
POMDP:只有视觉输入、部分 IMU(不完整观测)
POMDP 的处理方式(实践中常用):
方法 1:历史帧堆叠
o_stacked = [o_{t-3}, o_{t-2}, o_{t-1}, o_t]
近似包含了历史信息
方法 2:循环神经网络(RNN/LSTM)
h_t = RNN(h_{t-1}, o_t)
h_t 编码了历史信息作为"隐状态"
方法 3:Transformer
使用注意力机制处理观测历史序列
在人形机器人行走中,通常将关节角度、角速度、IMU、上一步动作等拼接成状态向量,近似满足马尔可夫性。
MDP 全貌图
┌───────────────────────────┐
│ │
┌─────────────┤ 环境 │
│ reward rₜ │ 状态转移 P(s'|s,a) │
│ state sₜ₊₁ │ 奖励函数 R(s,a,s') │
│ └───────────────────────────┘
│ ▲
▼ │
┌─────────────┐ action aₜ │
│ │─────────────────────┘
│ Agent │
│ 策略 π(a|s)│
│ 价值 V(s) │
└─────────────┘
Agent 的目标:找到最优策略 π*,使得期望折扣累积奖励最大:
π* = argmax_π E_π[Σ γᵏ rₜ₊ₖ]
本章小结
MDP 五元组 (S, A, P, R, γ) 是 RL 的完整数学描述
核心概念关系:
策略 π → 回报 G → 价值函数 V,Q → 最优策略 π*
两个价值函数:
V^π(s) = 状态 s 的期望累积奖励
Q^π(s,a) = 状态 s 下动作 a 的期望累积奖励
最优目标:
找 π* 使得 V^π*(s) 对所有 s 都最大
下一章 我们假设 MDP 的模型(P 和 R)已知,推导如何用动态规划精确求解最优策略——这会给出 Bellman 方程的完整推导。