目标:从”估计价值”跨越到”改进策略”,掌握 Q-Learning 和 Sarsa——一个是现代深度 RL 的鼻祖,一个阐明了 On/Off-Policy 的本质区别。
6.1 广义策略迭代(GPI)框架
所有 RL 控制算法,本质上都是策略评估与策略改进的交替循环,统称广义策略迭代(Generalized Policy Iteration, GPI):
graph LR
A[策略 π] -->|评估| B[价值函数 Q^π]
B -->|改进| C[更好的策略 π']
C -->|评估| D[新价值函数 Q^π']
D -->|改进| E[...]
E -->|收敛| F[最优 π* 和 Q*]
无模型控制的关键变化:
- 不用 $V(s)$,而用 $Q(s,a)$——因为改进策略时需要知道每个动作的价值,而在没有模型的情况下 $V(s)$ 做不到这点
- 评估和改进不等到收敛就交替进行(在线学习)
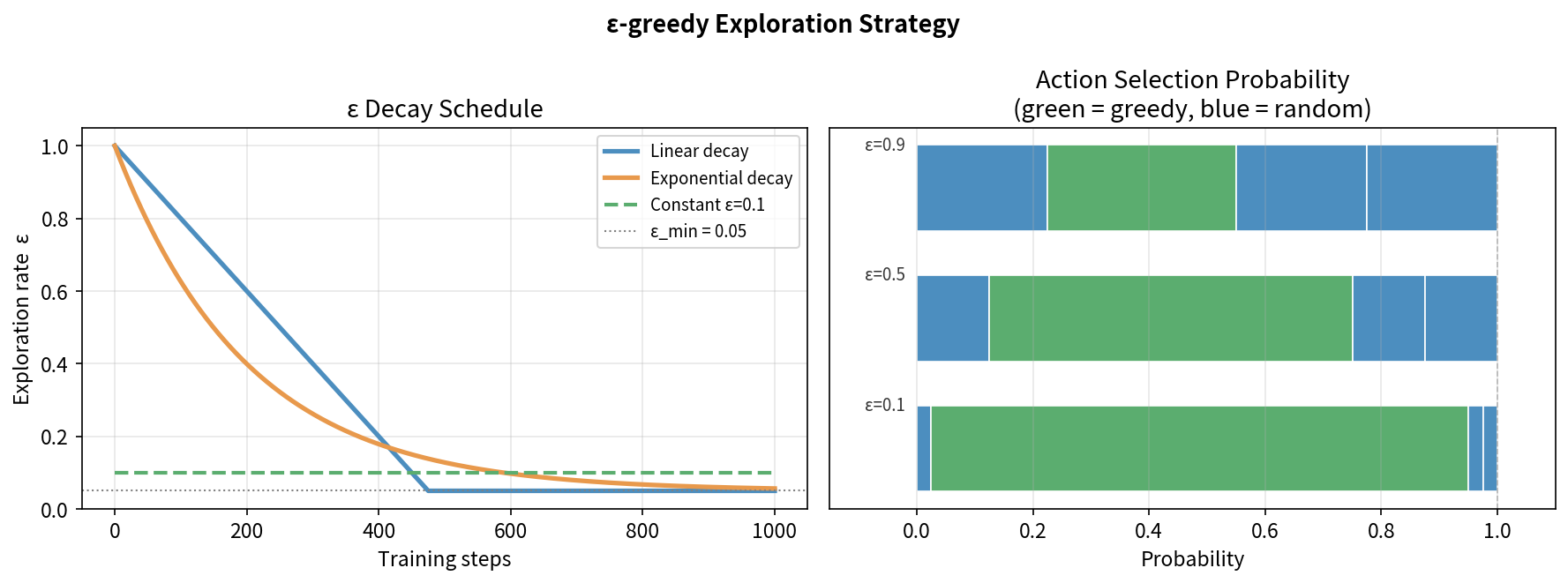
6.2 ε-greedy 策略:探索与利用
纯贪心策略(完全利用):
\[\pi(s) = \arg\max_a Q(s, a)\]问题:如果某个动作从未被探索,其 $Q$ 值不准确,却可能永远不被选择。
ε-greedy 策略(探索与利用的平衡):
\[\pi(a|s) = \begin{cases} 1 - \varepsilon + \frac{\varepsilon}{|\mathcal{A}|} & \text{若 } a = \arg\max_{a'} Q(s,a') \\ \frac{\varepsilon}{|\mathcal{A}|} & \text{其他动作} \end{cases}\]ε = 0.1 时:
90% 概率:选当前最优动作(利用)
10% 概率:随机选择(探索)
训练初期:ε 较大(多探索,数据少时 Q 不准)
训练后期:ε 减小(多利用,Q 已经收敛)
ε 的衰减策略:ε_t = ε₀ · decay^t 或 ε_t = ε₀/sqrt(t)
6.3 Sarsa:On-Policy TD 控制
Sarsa 得名于它使用的五元组:State, Action, Reward, State, Action。
Sarsa 更新规则
\[Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_t + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t) \right]\]注意:$a_{t+1}$ 是按当前策略(ε-greedy)实际选择的下一个动作。
算法:Sarsa
────────────────────────────────────────────────────
初始化:Q(s,a) = 0 对所有 s,a
对每个 Episode:
初始化 s
按 ε-greedy 选择 a ← π(s)
循环直到终止:
执行 a,观测 r, s'
按 ε-greedy 选择 a' ← π(s') ← 按当前策略选下一动作
Q(s,a) ← Q(s,a) + α[r + γQ(s',a') - Q(s,a)]
s ← s', a ← a'
关键:Sarsa 用实际执行的 $a’$ 来更新——它评估的是 ε-greedy 策略本身(包括探索)。
6.4 Q-Learning:Off-Policy TD 控制
Q-Learning(Watkins, 1989)是 RL 史上最重要的算法之一,是 DQN 的前身。
Q-Learning 更新规则
\[Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_t + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \right]\]注意区别:用 $\max_{a’} Q(s_{t+1}, a’)$ 而非 $Q(s_{t+1}, a_{t+1})$——这意味着更新假设下一步选最优动作,不管实际执行什么。
算法:Q-Learning
────────────────────────────────────────────────────
初始化:Q(s,a) = 0 对所有 s,a
对每个 Episode:
初始化 s
循环直到终止:
按 ε-greedy 选择 a(行为策略,带探索)
执行 a,观测 r, s'
Q(s,a) ← Q(s,a) + α[r + γ·max_{a'}Q(s',a') - Q(s,a)]
s ← s'
↑ 注意:更新用 max,而非实际选的 a'
Q-Table 结构与更新机制
Q-Learning 维护一张状态-动作值表,记录每个 $(s, a)$ 对的预期累积奖励。策略由表中每行的最大值决定:$\pi(s) = \arg\max_a Q(s, a)$。

更新公式中各项含义:
\[\underbrace{Q(s,a)}_{\text{New Q Value}} \leftarrow \underbrace{Q(s,a)}_{\text{Old Q Value}} + \alpha \underbrace{\left[\underbrace{r + \gamma \max_{a'} Q(s', a')}_{\text{TD Target}} - Q(s,a)\right]}_{\text{TD error}}\]- TD error(时序差分误差):目标值与当前估计的差距,驱动更新
- 学习率 α:控制每次更新的步长(0~1)
- 折扣因子 γ:控制对未来奖励的重视程度(0~1)
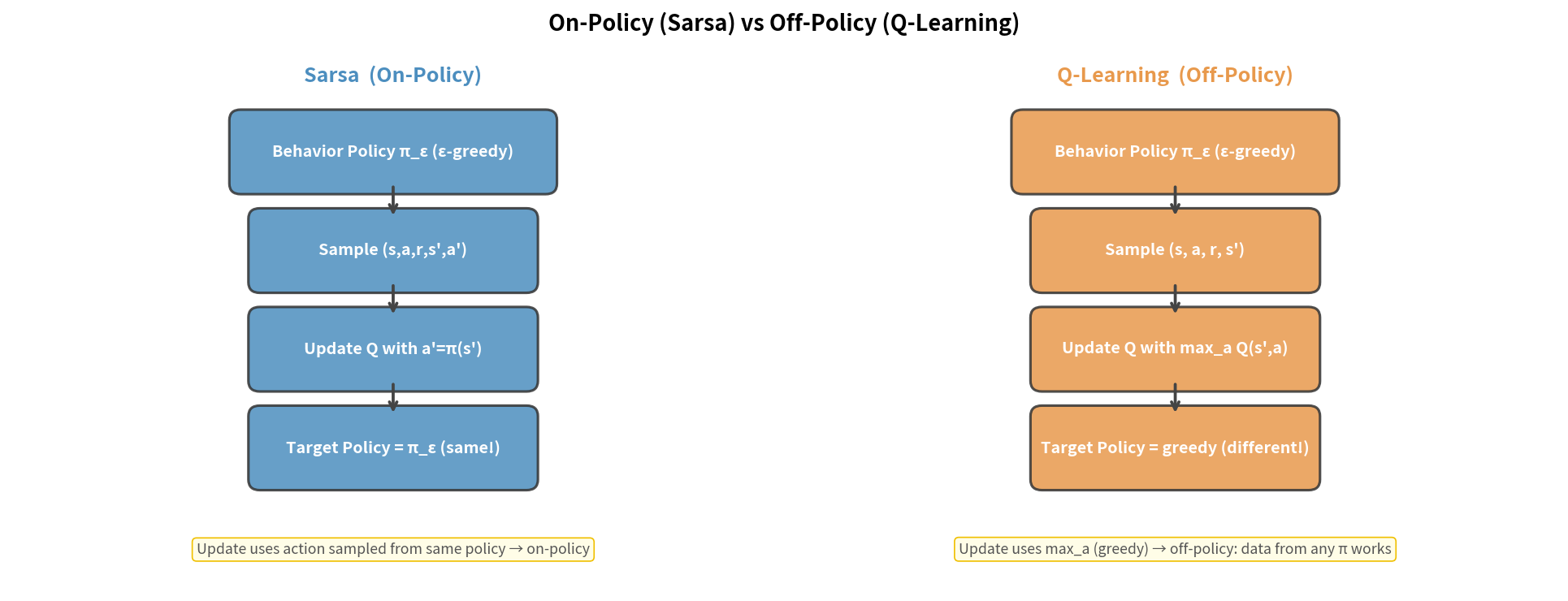
6.5 On-Policy vs Off-Policy 的本质区别
这是 RL 中一个核心概念,深刻影响着算法设计。
┌─────────────────────────────────────────────────────────┐
│ 行为策略 vs 目标策略 │
│ │
│ 行为策略(Behavior Policy):实际执行动作、收集数据的策略 │
│ 目标策略(Target Policy) :我们想学习和优化的策略 │
│ │
│ On-Policy :行为策略 = 目标策略 │
│ Off-Policy:行为策略 ≠ 目标策略 │
└─────────────────────────────────────────────────────────┘
Sarsa(On-Policy):
- 用 ε-greedy 策略收集数据,也评估这个策略
- “我学的就是我在用的策略”
- 结果:学到一个安全但略保守的策略(包含探索的成本)
Q-Learning(Off-Policy):
- 用 ε-greedy 策略收集数据(带探索)
- 但评估最优(greedy)策略(不带探索)
- “我用随机策略探索,但学的是最优贪心策略”
- 结果:可以学到最优确定性策略
经典例子:悬崖行走(Cliff Walking)
┌──────────────────────────────────────┐
│ . . . . . . . . . . . . . . . . . . │
│ S * * * * * * * * * * * * * * * * G │
│ ↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑ │
│ 悬崖(-100 奖励) │
└──────────────────────────────────────┘
Q-Learning:学到沿悬崖边缘走的最短路径(最优但冒险)
Sarsa: 学到绕远路走的安全路径(次优但鲁棒)
原因:Q-Learning 评估 max 策略(没有偶然掉崖的风险),
Sarsa 评估 ε-greedy 策略(偶尔会随机动作掉崖,
所以学会了远离悬崖)
On-Policy vs Off-Policy 全面对比

6.6 Q-Learning 的收敛性
定理(Watkins & Dayan, 1992):
在满足以下条件时,Q-Learning 以概率 1 收敛到 $Q^*$:
- 所有状态-动作对被无限次访问(充分探索)
- 学习率 $\alpha_t$ 满足 Robbins-Monro 条件: $\sum_t \alpha_t = \infty, \quad \sum_t \alpha_t^2 < \infty$ 例如:$\alpha_t = \frac{1}{t}$ 满足此条件
直觉:条件 1 保证没有”死角”,条件 2 保证学习率衰减但总量足够大。
实践中:学习率通常取固定值(如 0.001),通过经验回放保证状态覆盖,省略严格的数学收敛条件。
6.7 Double Q-Learning:消除最大化偏差
最大化偏差的来源
Q-Learning 中的 $\max_{a’} Q(s’, a’)$ 存在一个系统性高估问题:
当 Q 值有噪声估计时(早期训练总是有噪声),$\max$ 操作会选中高估最多的那个动作:
\[\mathbb{E}[\max_a Q(s,a)] \geq \max_a \mathbb{E}[Q(s,a)]\]等号当且仅当估计无噪声时成立。这导致 Q 值被持续高估,可能导致次优策略。
Double Q-Learning 的解决方案(Hasselt, 2010)
用两个独立的 Q 函数:$Q_A$ 和 $Q_B$,一个选动作,另一个评估价值:
\[Q_A(s,a) \leftarrow Q_A(s,a) + \alpha\left[r + \gamma Q_B(s', \arg\max_{a'} Q_A(s', a')) - Q_A(s,a)\right]\]普通 Q-Learning:用同一个 Q 既选动作又评估价值
→ 放大了估计误差
Double Q-Learning:
A 负责"选最优动作":a* = argmax_{a'} Q_A(s', a')
B 负责"评估动作价值":target = Q_B(s', a*)
→ 解耦选择与评估,减小高估偏差
Double DQN(第7章)将此思想扩展到深度网络。
6.8 表格型方法的极限
本章所有算法都用表格存储 $Q(s,a)$——对每个 $(s,a)$ 对维护一个数值。
状态数爆炸举例:
离散化机器人关节状态(简化):
12 个关节角度,每维 10 个格子 → 10¹² = 万亿个状态
× 12 个动作维度 → 表格无法存储
表格 Q-Learning 的实际上限:
✓ 几千个状态的格子世界
✓ 简单的棋盘游戏
✗ 机器人连续控制
✗ Atari 游戏(像素输入)
✗ 任何高维连续空间
解决方案:用神经网络 $Q_\theta(s,a)$ 替代表格——深度 Q 网络(DQN,第7章)。
本章对比总结
┌─────────────────────────────────────────────────────────┐
│ Sarsa vs Q-Learning 核心对比 │
├───────────────────┬────────────────┬────────────────────┤
│ 属性 │ Sarsa │ Q-Learning │
├───────────────────┼────────────────┼────────────────────┤
│ Policy 类型 │ On-Policy │ Off-Policy │
│ 目标公式 │ r+γQ(s',a') │ r+γmax Q(s',a') │
│ a' 来自 │ 当前策略(ε-gr) │ max(最优) │
│ 学到的策略 │ ε-greedy 策略 │ 最优贪心策略 │
│ 安全性 │ 更保守 │ 更激进(最优) │
│ 收敛到 │ Q^{ε-greedy} │ Q* │
└───────────────────┴────────────────┴────────────────────┘
延伸阅读
- Watkins, C.J.C.H. & Dayan, P. (1992). Q-Learning. Machine Learning — Q-Learning 原始论文 — PDF
- Hasselt, H.V. (2010). Double Q-Learning. NeurIPS — Double Q-Learning 原始论文 — PDF
- Sutton & Barto, Reinforcement Learning: An Introduction (2nd Ed.), Chapter 6 — 免费在线版
- David Silver UCL Course, Lecture 5: Model-Free Control — YouTube