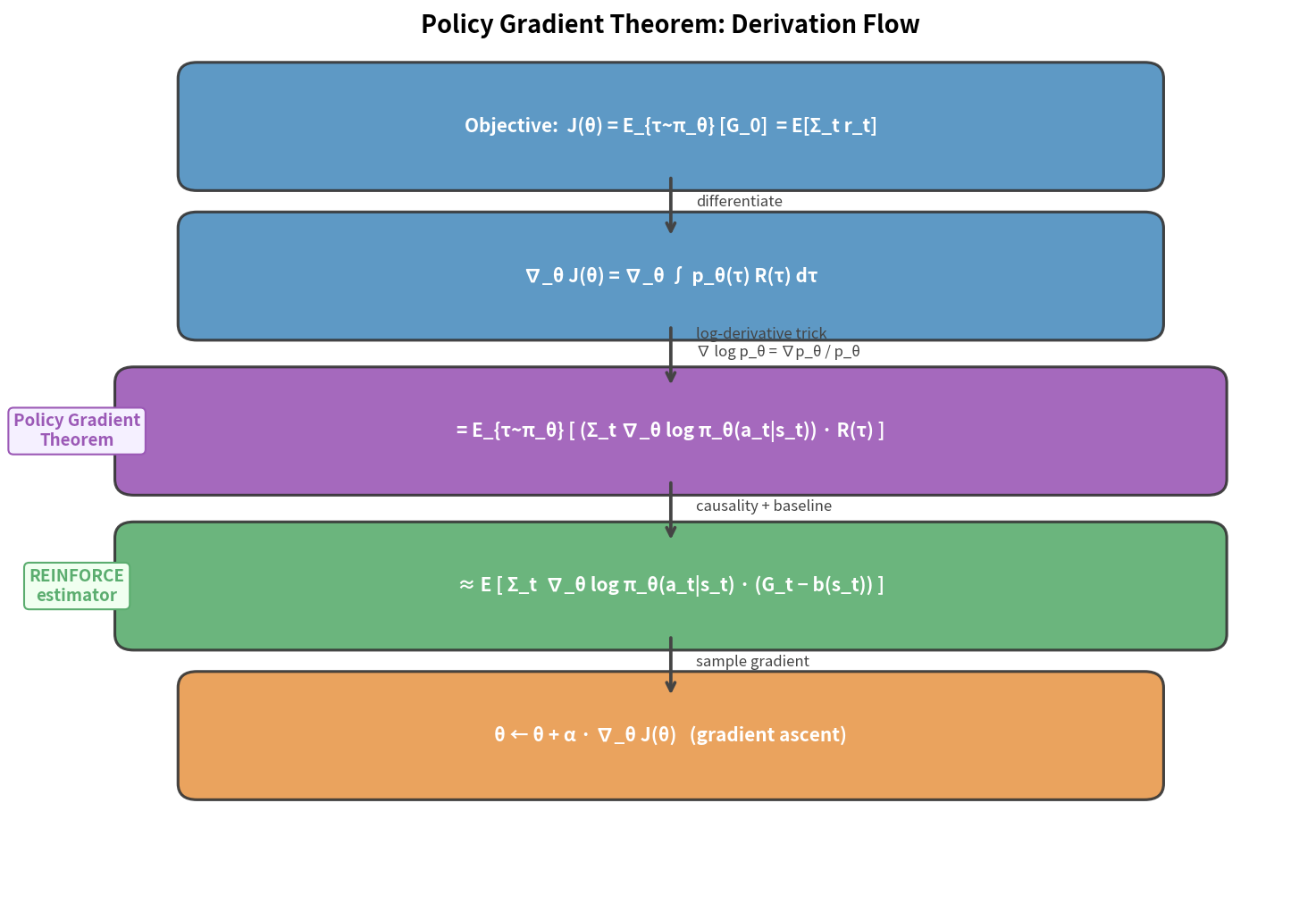
目标:跳出”先学价值函数,再推策略”的思路,直接对策略参数求梯度。推导策略梯度定理,这是 PPO、SAC 等现代算法的数学基础。
8.1 为什么需要策略梯度
DQN 的方法路线:学 Q 函数 → 从 Q 推出策略(取 argmax)。
对于连续动作空间(机器人控制的关节力矩),这行不通:
连续动作空间中 argmax Q(s,a) 的问题:
a* = argmax_a Q_θ(s, a)
a 是连续的,无法枚举所有 a 取 max
需要每步做内层优化 → 计算量爆炸
强化学习按策略优化方式的分类:
| 分类 | 核心思想 | 特点 | 代表算法 |
|---|---|---|---|
| 基于价值(Value-Based) | 优化价值函数 $Q(s,a)$,间接推导策略 | 策略隐式,适合离散动作空间 | Q-Learning, DQN, SARSA |
| 基于策略(Policy-Based) | 直接优化策略函数 $\pi_\theta(a|s)$ | 可处理连续动作,高方差但探索强 | REINFORCE, TRPO, PPO |
| Actor-Critic | 结合价值函数(Critic)和策略函数(Actor) | 兼具两者优点,减少方差 | A2C, SAC, DDPG, PPO |
策略梯度的思路:直接将策略参数化 $\pi_\theta$,用梯度上升直接优化期望回报:
\[\theta \leftarrow \theta + \alpha \nabla_\theta J(\theta)\]其中 $J(\theta) = \mathbb{E}{\tau\sim\pi\theta}[G_0]$ 是期望累积奖励。
8.2 策略参数化
离散动作:Softmax 策略
\[\pi_\theta(a|s) = \frac{\exp(\phi(s,a)^\top \theta)}{\sum_{a'} \exp(\phi(s,a')^\top \theta)}\]或直接用神经网络输出 logit,然后 Softmax。
连续动作:Gaussian 策略(机器人控制常用)
\[\pi_\theta(a|s) = \mathcal{N}(\mu_\theta(s), \sigma_\theta^2(s))\] \[\log \pi_\theta(a|s) = -\frac{(a - \mu_\theta(s))^2}{2\sigma_\theta^2(s)} - \log \sigma_\theta(s) - \frac{1}{2}\log(2\pi)\]网络结构(机器人关节控制):
状态 s (48维)
↓
MLP(256, 256) + Tanh
↓
├─ 均值头: Linear(12) + Tanh → μ (12个关节力矩均值)
└─ 对数标准差: 可学参数 log σ → σ (可固定或可学习)
采样动作: a ~ N(μ, σ²) = μ + σ·ε, ε~N(0,I)
8.3 策略梯度定理(完整推导)
目标函数(Episode 任务):
\[J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}[G_0] = \sum_\tau P(\tau; \theta) G(\tau)\]其中 $P(\tau; \theta)$ 是轨迹 $\tau$ 在策略 $\pi_\theta$ 下的概率:
\[P(\tau; \theta) = p(s_0) \prod_{t=0}^{T-1} \pi_\theta(a_t|s_t) \mathcal{P}(s_{t+1}|s_t, a_t)\]对目标函数求梯度:
\[\nabla_\theta J(\theta) = \nabla_\theta \sum_\tau P(\tau; \theta) G(\tau)\]利用对数导数技巧(log-derivative trick):
\[\nabla_\theta P(\tau; \theta) = P(\tau; \theta) \nabla_\theta \log P(\tau; \theta)\]代入:
\[\nabla_\theta J(\theta) = \sum_\tau P(\tau; \theta) \nabla_\theta \log P(\tau; \theta) G(\tau) = \mathbb{E}_{\tau \sim \pi_\theta}[\nabla_\theta \log P(\tau; \theta) G(\tau)]\]展开 $\log P(\tau; \theta)$:
\[\log P(\tau; \theta) = \log p(s_0) + \sum_{t=0}^{T-1} \left[\log \pi_\theta(a_t|s_t) + \log \mathcal{P}(s_{t+1}|s_t, a_t)\right]\]对 $\theta$ 求梯度时,$\log p(s_0)$ 和 $\log \mathcal{P}$ 与 $\theta$ 无关,梯度为零:
\[\nabla_\theta \log P(\tau; \theta) = \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t)\]策略梯度定理(最终结果):
\[\boxed{\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}\left[\sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot G_t\right]}\]重要含义:
- 不需要知道环境模型 $\mathcal{P}$(无模型!)
- 可以用蒙特卡洛采样估计(用实际轨迹)
- $G_t$(回报)高的轨迹,其动作的对数概率梯度被放大——”好的动作更可能被选择”
8.4 REINFORCE 算法
将策略梯度定理直接实现为 MC 估计:
\[\nabla_\theta J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t^{(i)}|s_t^{(i)}) \cdot G_t^{(i)}\]算法:REINFORCE(Williams, 1992)
────────────────────────────────────────────────────
初始化:策略网络参数 θ
对每个 Episode:
生成轨迹:τ = {s₀,a₀,r₀, s₁,a₁,r₁, ..., s_T}
计算每步回报:G_t = Σ_{k=t}^{T} γ^{k-t} r_k
对每个时间步 t:
∇θ += ∇_θ log π_θ(a_t|s_t) · G_t
更新:θ ← θ + α · ∇θ / T
直觉图示:
一次 Episode:
步骤 动作 奖励 回报 G_t
t=0 a=右 r=+0 G=+2 → 小幅增加 π(右|s₀) 的概率
t=1 a=右 r=+2 G=+2 → 小幅增加 π(右|s₁) 的概率
t=2 a=上 r=+0 G=+0 → 不增不减
t=3 a=左 r=-1 G=-1 → 降低 π(左|s₃) 的概率
好回报 → 强化对应动作
差回报 → 抑制对应动作
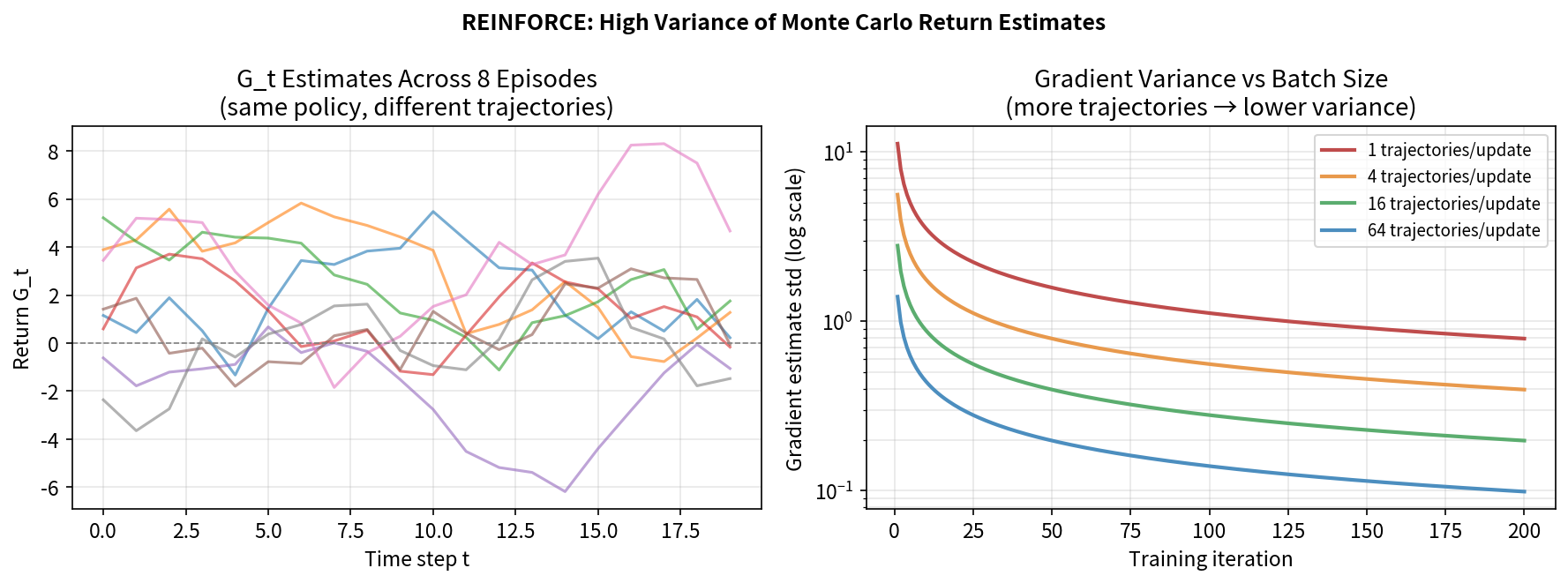
8.5 高方差问题与基线技术
REINFORCE 的最大问题:方差极高。
方差来源:$G_t$ 是整条轨迹的随机回报,各轨迹差异巨大。同一个状态-动作对在不同轨迹中,$G_t$ 可能相差悬殊。
后果:梯度估计噪声很大,训练需要大量样本才能收敛。
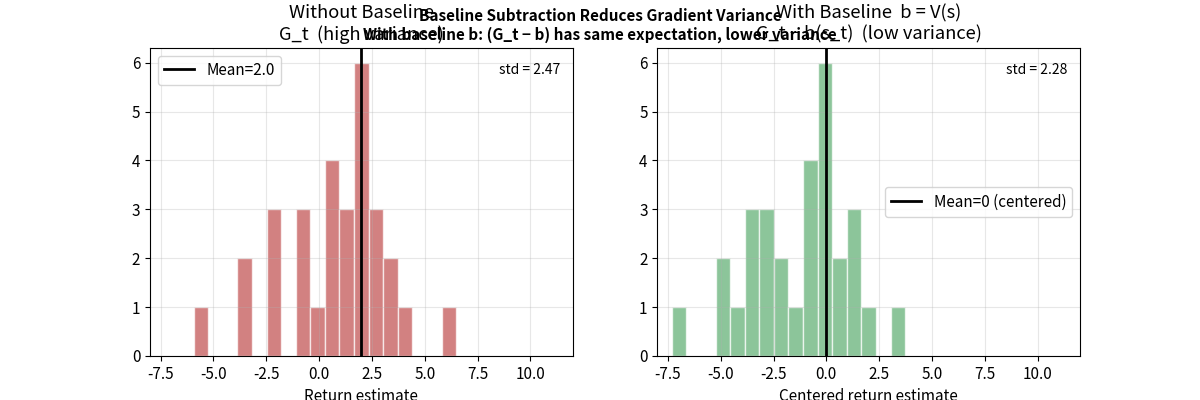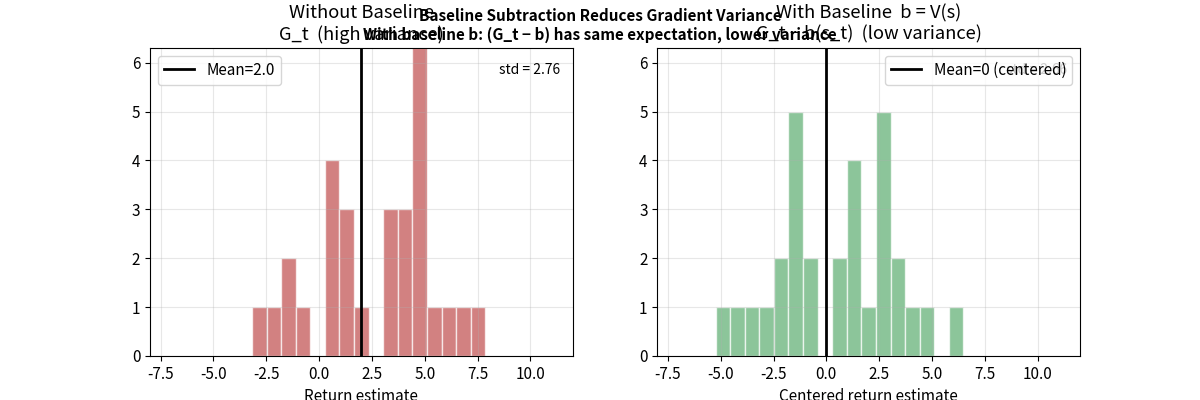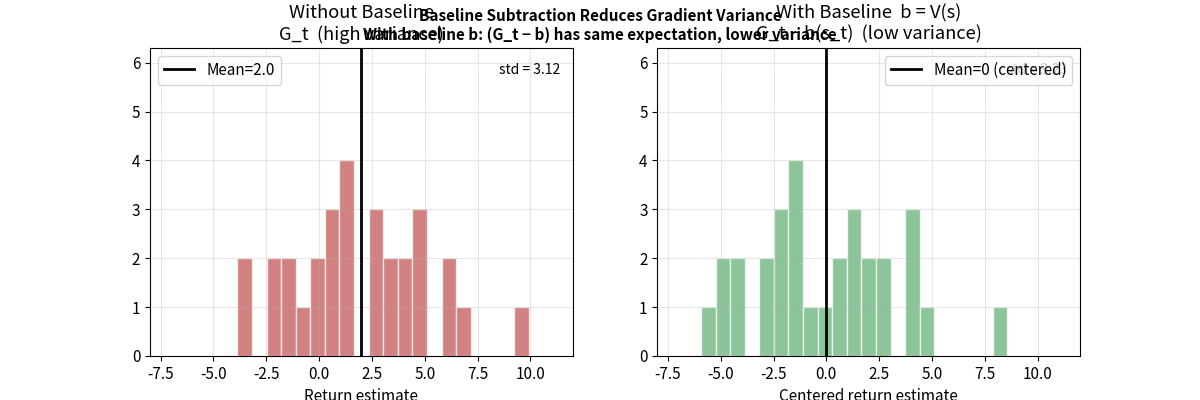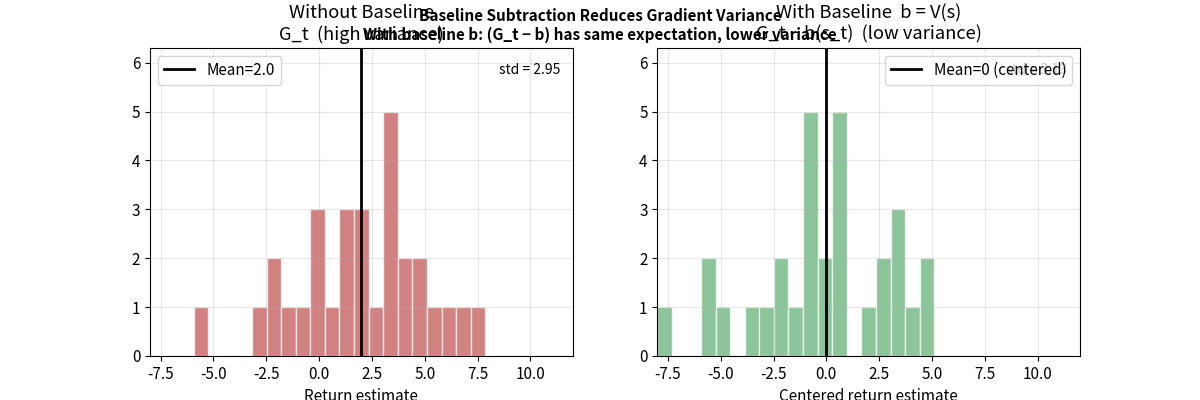
基线(Baseline)技术
在不引入偏差的前提下,减小方差:
\[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}\left[\sum_{t} \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot (G_t - b(s_t))\right]\]其中 $b(s_t)$ 是基线函数,可以是任何仅与状态有关的函数。
为什么减去基线不改变期望(证明):
\[\mathbb{E}_\pi[\nabla_\theta \log \pi_\theta(a|s) \cdot b(s)] = b(s) \cdot \underbrace{\mathbb{E}_\pi[\nabla_\theta \log \pi_\theta(a|s)]}_{=0}\]因为 $\mathbb{E}{a\sim\pi}[\nabla\theta \log \pi_\theta(a \vert s)] = \nabla_\theta \underbrace{\mathbb{E}{a\sim\pi}[1]}{=1} = 0$
所以减去基线不影响期望,但能大幅降低方差。
常用基线:状态价值函数 $V(s_t)$
\[G_t - V^\pi(s_t) = G_t - \mathbb{E}_\pi[G_t | s_t]\]这个差值叫做优势函数(Advantage Function):
\[A^\pi(s_t, a_t) = Q^\pi(s_t, a_t) - V^\pi(s_t)\]含义:动作 $a_t$ 相对于平均水平好多少?
A > 0:这个动作比平均情况好 → 增加其概率
A < 0:这个动作比平均情况差 → 降低其概率
A = 0:与平均持平 → 不变
更新的策略梯度(使用优势):
\[\boxed{\nabla_\theta J(\theta) \approx \mathbb{E}_\pi\left[\sum_{t} \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot A^\pi(s_t, a_t)\right]}\]8.6 因果性:去掉未来无关的回报
仔细分析策略梯度,时刻 $t$ 的动作 $a_t$ 不应该影响之前时刻的奖励(因果性)。
精确的策略梯度应该是:
\[\nabla_\theta J(\theta) = \mathbb{E}_\pi\left[\sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot \left(\sum_{t'=t}^{T} \gamma^{t'-t} r_{t'}\right)\right]\]即每个时刻只乘以从该时刻开始的回报(因果一致的 $G_t$),而不是整条轨迹的总回报。
8.7 策略梯度 vs 值函数方法
┌─────────────────────────────────────────────────────────┐
│ 策略梯度 vs 值函数方法 │
├──────────────────┬──────────────────┬───────────────────┤
│ │ 值函数方法(DQN) │ 策略梯度(REINFORCE│
├──────────────────┼──────────────────┼───────────────────┤
│ 学习对象 │ Q(s,a) 值函数 │ π(a|s) 策略 │
│ 动作空间 │ 离散 │ 离散+连续 │
│ 策略类型 │ 确定性(argmax) │ 随机(分布) │
│ 样本效率 │ 高(Off-policy) │ 低(On-policy) │
│ 收敛稳定性 │ 不稳定(高估等) │ 收敛更稳定 │
│ 连续控制 │ 困难 │ 天然适合 │
│ 探索机制 │ ε-greedy(显式) │ 策略本身(内置) │
└──────────────────┴──────────────────┴───────────────────┘

本章小结
策略梯度核心公式:
∇_θ J(θ) = E_π[Σ_t ∇_θ log π_θ(a_t|s_t) · A(s_t, a_t)]
三个关键技巧:
1. log-derivative trick → 不需要模型
2. 因果性 → 只用当前时刻之后的回报
3. 基线(Baseline) → 减小方差,用 A = G - V 替代 G
问题:REINFORCE 方差仍然很高(MC 回报)
解决:Actor-Critic(下一章)
= 策略梯度 + 实时的价值函数估计(TD 而非 MC)
延伸阅读
- Williams, R.J. (1992). Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Machine Learning — REINFORCE 原始论文 — PDF
- Sutton et al. (1999). Policy Gradient Methods for Reinforcement Learning with Function Approximation. NeurIPS — 策略梯度定理论文 — PDF
- Sutton & Barto, Reinforcement Learning: An Introduction (2nd Ed.), Chapter 13 — 免费在线版
- Spinning Up in Deep RL(OpenAI)策略梯度介绍 — spinningup.openai.com