目标:理解从 TRPO 到 PPO 的演进逻辑,掌握 PPO-Clip 的完整推导,以及它在人形机器人行走训练中的实际应用。
10.1 策略更新的稳定性问题
问题的本质
普通策略梯度(A2C/REINFORCE)用梯度上升直接更新策略:
\[\theta \leftarrow \theta + \alpha \nabla_\theta J(\theta)\]这有一个根本问题:步长难以控制。
步长太大(α 大):
旧策略 π_old → 新策略 π_new 差异巨大
→ 训练数据(在 π_old 下采集)与 π_new 不匹配
→ 价值估计失效,训练崩溃
步长太小(α 小):
→ 学习速度极慢
→ 样本效率低下
参数空间的步长 ≠ 策略空间的步长:学习率 $\alpha$ 控制的是参数 $\theta$ 的变化,但策略 $\pi_\theta$ 的实际变化是非线性的、难以预料的。
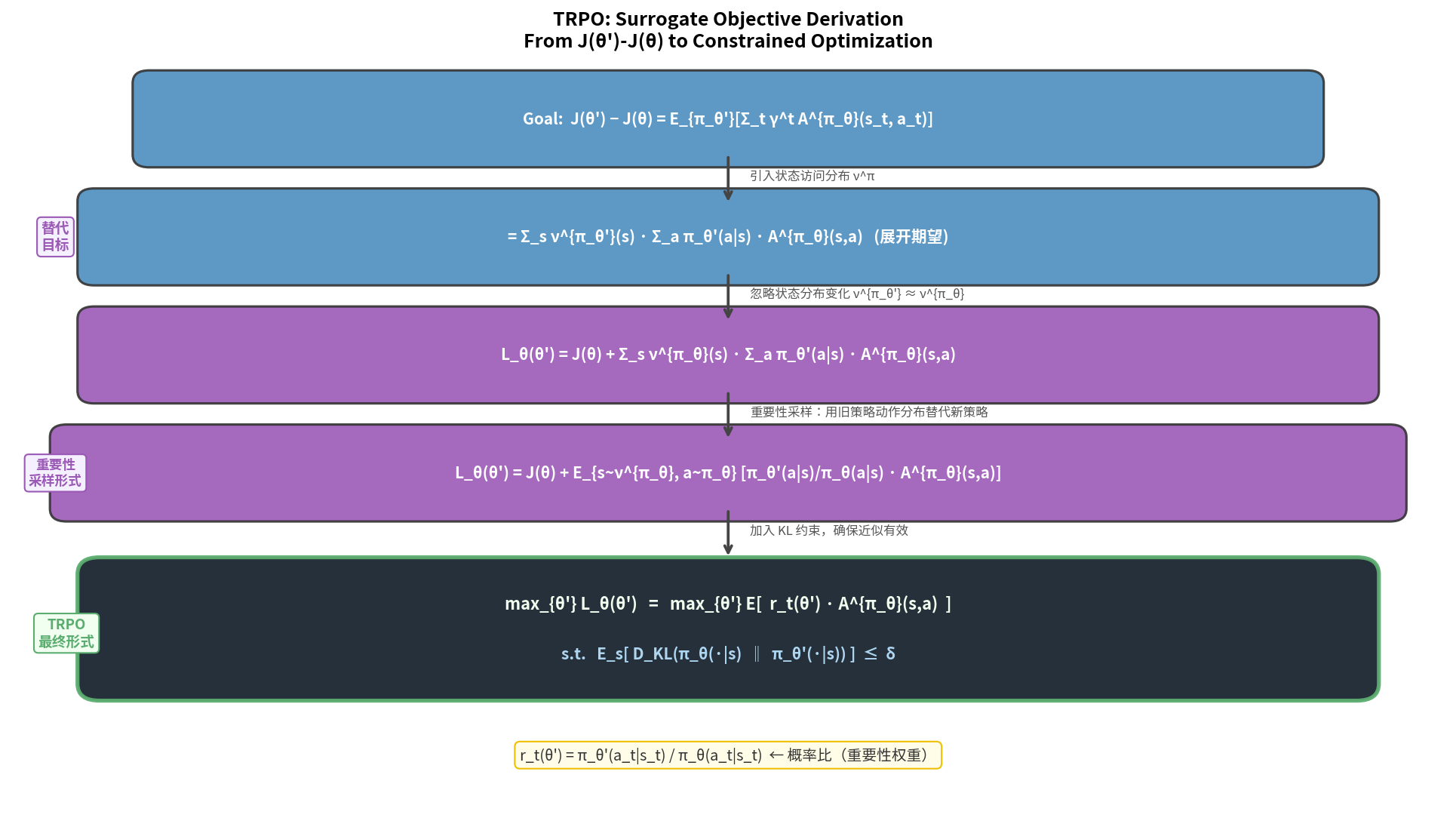
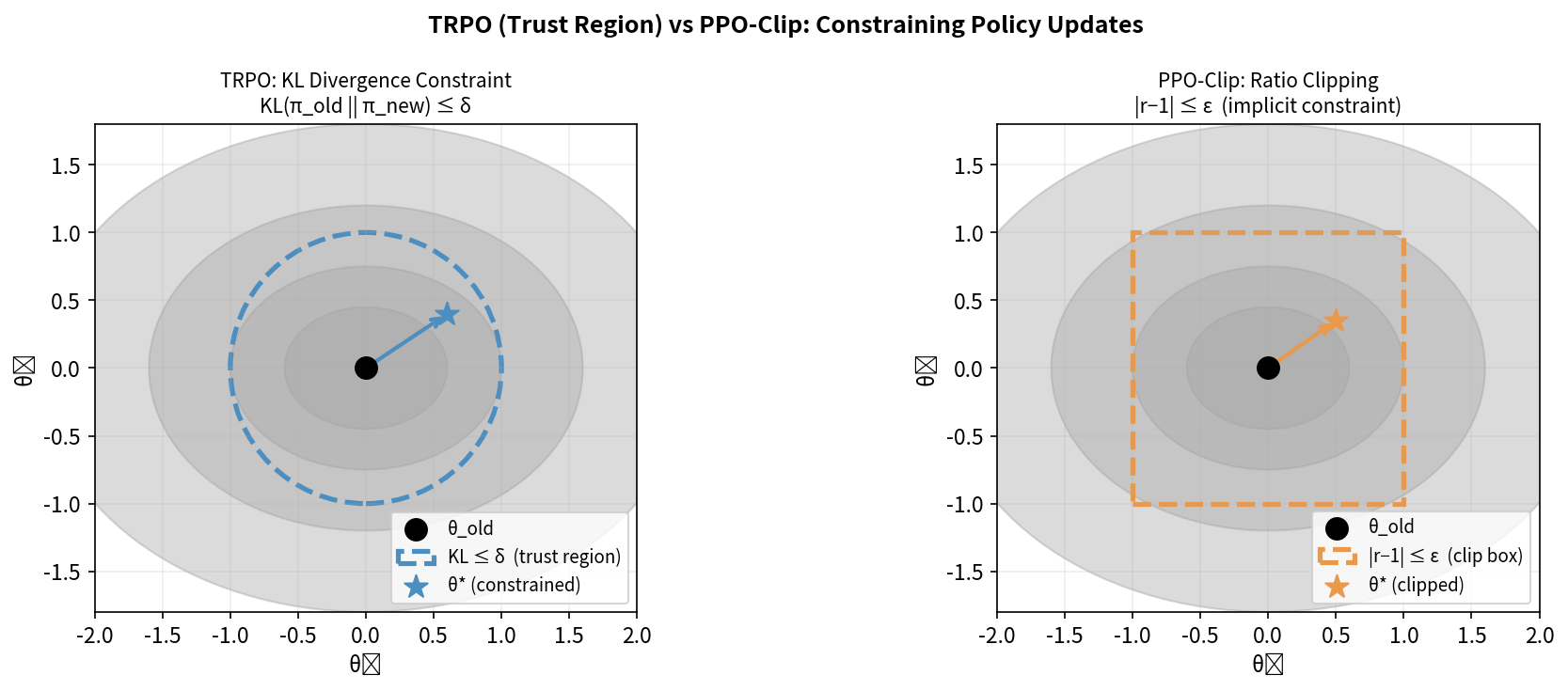
10.2 TRPO:信任域策略优化
核心思想:在策略空间(而非参数空间)限制更新步长——用 KL 散度约束新旧策略的差异。
\[\max_\theta \quad \mathbb{E}_{s,a \sim \pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)} A^{\pi_{\theta_{\text{old}}}}(s,a)\right]\] \[\text{s.t.} \quad \mathbb{E}_s\left[D_{KL}(\pi_{\theta_{\text{old}}}(\cdot|s) \| \pi_\theta(\cdot|s))\right] \leq \delta\]概率比(Importance Ratio) $r_t(\theta)$:
\[r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)}\]这是重要性采样(Importance Sampling)的系数,允许用旧策略采集的数据来估计新策略的性能。
代理目标(Surrogate Objective):
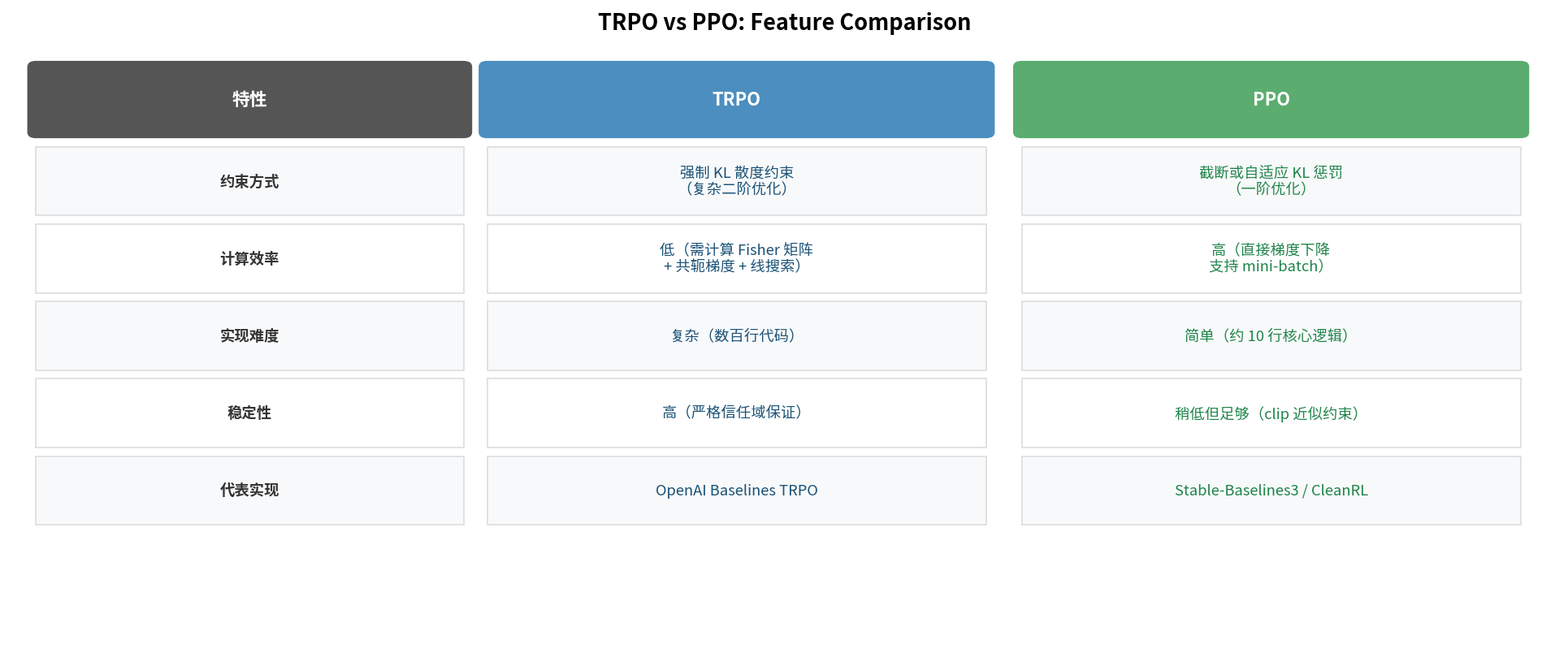
\[L^{CPI}(\theta) = \mathbb{E}_t\left[r_t(\theta) \hat{A}_t\right]\]TRPO 的问题:KL 约束需要二阶优化(共轭梯度 + 线搜索),实现复杂,计算昂贵,难以与深度网络配合使用。
论文:Trust Region Policy Optimization (Schulman et al., 2015) — arXiv:1502.05477
10.3 PPO-Clip:TRPO 的工程简化
PPO(Schulman et al., 2017)用简单的裁剪(Clip)操作替代了 KL 约束,达到类似的效果但实现极为简洁。
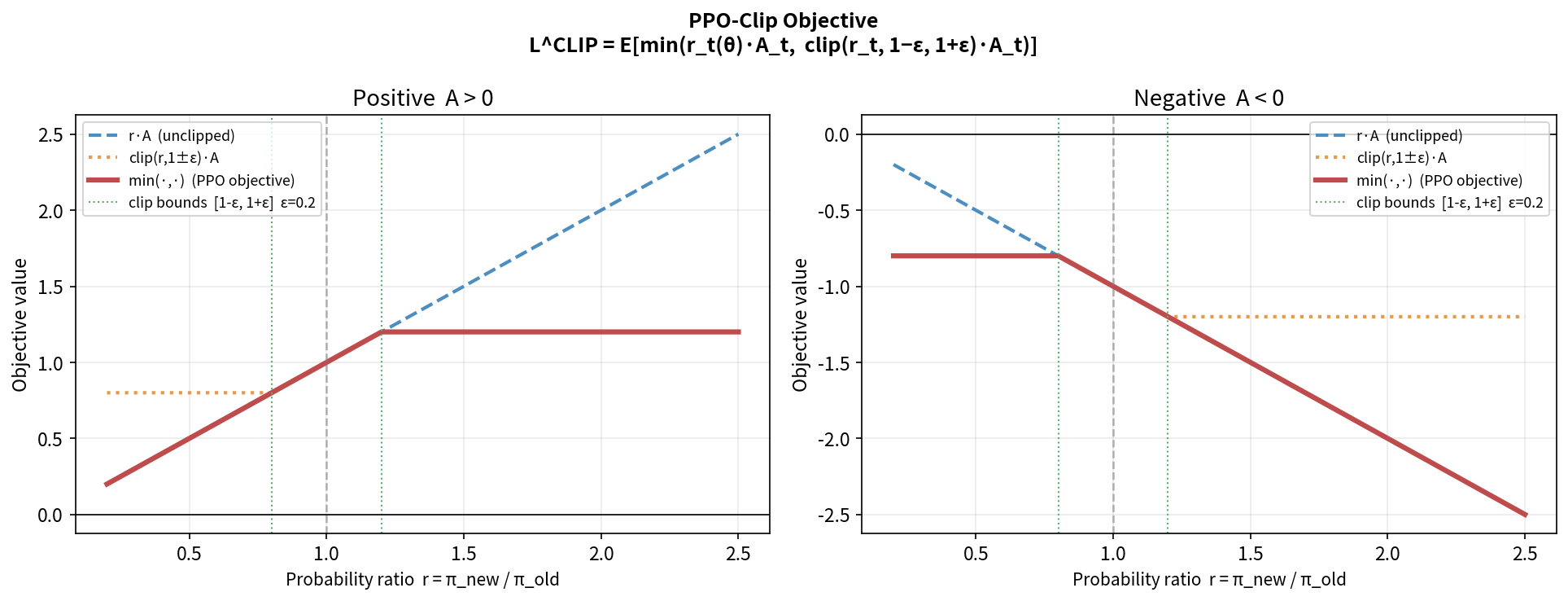
PPO-Clip 目标函数
\[L^{CLIP}(\theta) = \mathbb{E}_t\left[\min\left(r_t(\theta)\hat{A}_t, \;\text{clip}(r_t(\theta), 1-\varepsilon, 1+\varepsilon)\hat{A}_t\right)\right]\]其中 $\varepsilon$ 通常取 $0.1$ 或 $0.2$,clip(x, 1-ε, 1+ε) 将 $r_t$ 截断到 $[1-\varepsilon, 1+\varepsilon]$。
逐情况分析(这是 PPO 的核心!)
情况 1:$\hat{A}_t > 0$(当前动作好于平均)
我们希望增加动作概率($r_t > 1$),但不要增加太多:
r_t·Â 裁剪后的 r_t·Â
│ │
│ / │ ___/ ← 在 r_t = 1+ε 处截断
│ / │ /
│ / │/
─┼─────── r_t ─┼───────── r_t
0 1 1+ε 0 1 1+ε
取 min → 当 r_t > 1+ε 时,不再从中获益
目的:防止策略变化过大
情况 2:$\hat{A}_t < 0$(当前动作差于平均)
我们希望降低动作概率($r_t < 1$),但不要降低太多:
取 min 等价于:当 r_t < 1-ε 时,不再继续惩罚
防止策略激进地压低某些动作
完整 clip 效果可视化:
L^CLIP 关于 r_t 的函数形状:
 > 0  < 0
目标值 ___________ |
/ (上限=1+ε 处截断) | \___________
/ / (下限=1-ε 处截断)
/ /
──────────/───────────── ──────/──────────────────
0 1 1+ε 1-ε 1
直觉总结:PPO-Clip 是一个悲观的(pessimistic)目标——当改变有利时,限制获益上限;当改变不利时,也限制损失下限。这确保了每次更新不会偏离旧策略太远。
10.4 PPO 完整损失函数
\[L^{PPO}(\theta) = \mathbb{E}_t\left[ L^{CLIP}(\theta) - c_1 L^{VF}(\theta) + c_2 H[\pi_\theta(\cdot|s_t)] \right]\]三项解释:
| 项 | 作用 |
|---|---|
| $L^{CLIP}$:策略损失 | 改进策略,限制更新步长 |
| $L^{VF} = (V_\theta(s_t) - G_t)^2$:价值损失 | 训练 Critic,提高优势估计准确性 |
| $H[\pi]$:熵正则 | 防止过早收敛到确定性策略,保持探索 |
典型超参数:$c_1 = 0.5$(价值损失权重),$c_2 = 0.01$(熵权重)
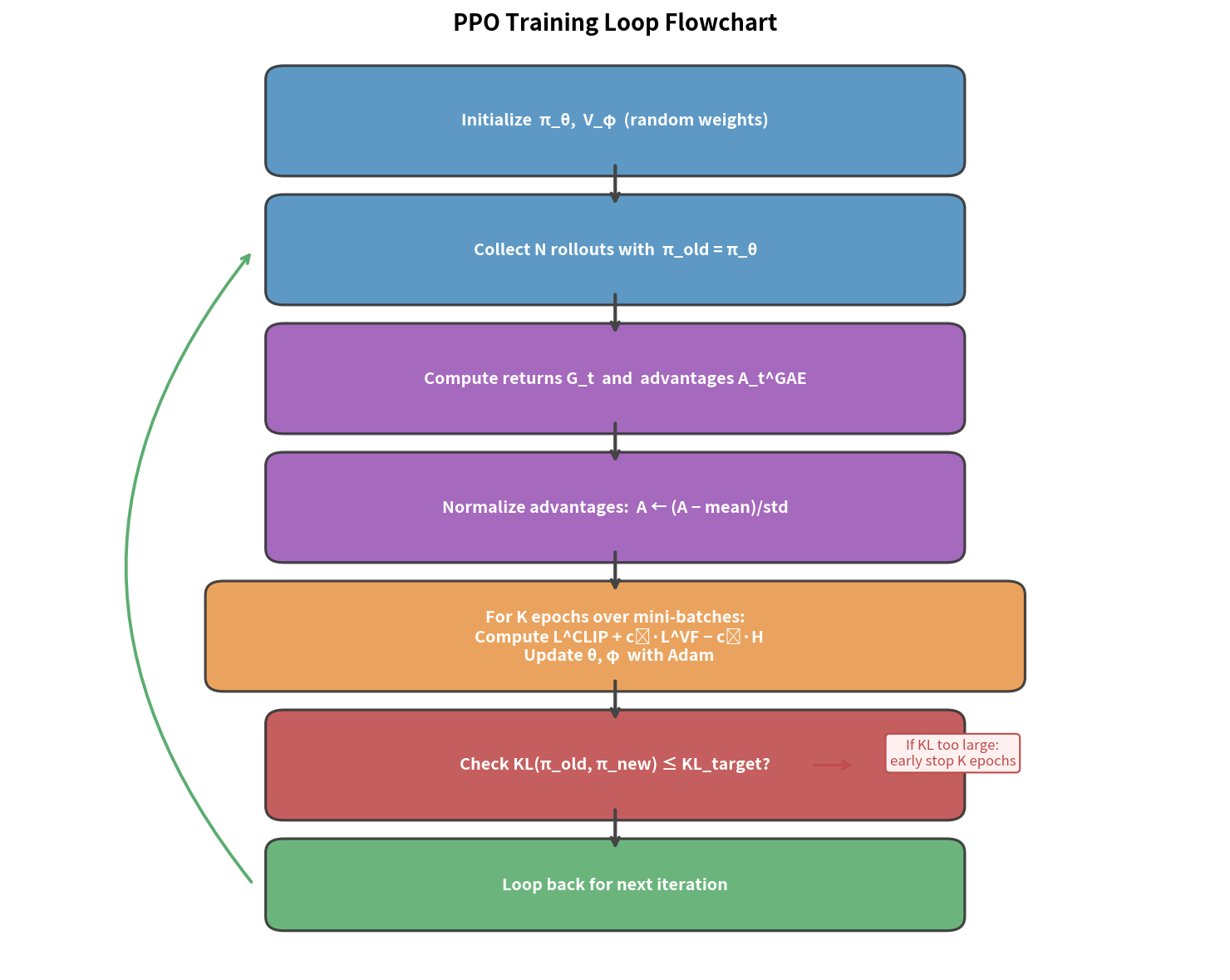
10.5 PPO 完整算法流程
PPO 算法(On-Policy)
────────────────────────────────────────────────────────────
初始化:Actor-Critic 网络 π_θ, V_w(通常共享除最后层外的参数)
循环(outer loop):
① 收集数据(Rollout):
用当前策略 π_{θ_old} 与环境交互 T 步(或 N 个 Episode)
存储:{s_t, a_t, r_t, s_{t+1}, done_t}
② 计算优势估计:
用 GAE 计算 Â_t(见第9章)
计算 returns: G_t = Â_t + V(s_t)
③ 归一化优势(提升稳定性):
Â_t ← (Â_t - mean(Â)) / (std(Â) + ε)
④ 多 epoch 更新(inner loop,K=4~10 次):
将数据分成 mini-batch(大小 M)
对每个 mini-batch:
计算 r_t(θ) = π_θ(a_t|s_t) / π_{θ_old}(a_t|s_t)
计算 L^CLIP, L^VF, H
计算总损失 L^PPO
Adam 梯度下降
⑤ 更新旧策略:θ_old ← θ
可选:若 KL(π_old‖π_new) > KL_target,提前停止
与 DQN 的关键区别:
DQN(Off-Policy):
数据可以来自历史策略(Replay Buffer)
每步数据都存储,反复使用
PPO(On-Policy):
每轮数据只能来自当前策略(同策略)
收集一批数据 → 多轮更新 → 丢弃 → 再收集
"用完即弃"的数据,但可多 epoch 充分利用
10.6 多 Worker 并行采集
PPO 在工程实现中通常使用多个并行环境来加速数据采集:
PPO 并行采集架构:
┌──────────────────────────────────────────┐
│ 策略网络 π_θ(单个,在 GPU 上) │
└──────────────────────────────────────────┘
│ 广播策略参数
├──── Worker 0: Env₀ → 采集 T 步
├──── Worker 1: Env₁ → 采集 T 步
├──── Worker 2: Env₂ → 采集 T 步
│ ...
└──── Worker N: Envₙ → 采集 T 步
汇总所有 N×T 条数据
→ 多 epoch mini-batch 训练
→ 更新 π_θ
→ 重复
Isaac Gym / Isaac Lab 的优势:将数千个仿真环境运行在单个 GPU 上,数据采集极快,大幅加速 PPO 训练。
10.7 PPO 超参数解析
| 超参数 | 典型值 | 说明 |
|---|---|---|
clip_param ε |
0.2 | Clip 的边界,控制策略变化幅度 |
n_steps T |
2048 | 每次 rollout 的步数 |
n_envs N |
4~8192 | 并行环境数 |
batch_size |
64~4096 | Mini-batch 大小 |
n_epochs K |
10 | 每批数据的训练轮数 |
lr |
3e-4 | Adam 学习率(通常线性衰减) |
gamma γ |
0.99 | 折扣因子 |
gae_lambda λ |
0.95 | GAE 参数 |
vf_coef $c_1$ |
0.5 | 价值损失权重 |
ent_coef $c_2$ |
0.01 | 熵正则权重 |
max_grad_norm |
0.5 | 梯度裁剪阈值 |
10.8 PPO 在 G1 机器人行走训练中的完整流程
以 Unitree G1 人形机器人行走控制为例,拆解 PPO 的完整训练过程:
环境配置(Isaac Gym/Lab):
并行环境数:4096 个机器人同时训练
仿真频率:200 Hz(dt=0.005s)
控制频率:50 Hz(每4步仿真更新一次动作)
状态空间:~45 维(关节角速度、IMU、步态相位...)
动作空间:12 维关节目标角度(PD 控制器跟踪)
PPO 配置:
rollout steps/env:24 步
total steps/update:24 × 4096 = 98,304 步
mini-batch size:4096(1 epoch)
n_epochs:5
clip ε:0.2
GAE λ:0.95
γ:0.99
lr:1e-3 → 余弦衰减
奖励函数(典型设计):
reward = (
+ 1.0 * tracking_lin_vel # 跟踪目标线速度
+ 0.5 * tracking_ang_vel # 跟踪目标角速度
- 0.01 * lin_vel_z_penalty # 惩罚竖直方向颤动
- 0.005* ang_vel_xy_penalty # 惩罚横滚/俯仰抖动
- 0.0001* torques_penalty # 惩罚大力矩(节能)
- 0.0025* dof_acc_penalty # 惩罚关节加速度过大
- 0.25 * collision_penalty # 惩罚自碰撞
+ 0.2 * feet_air_time # 奖励步态中的腾空时间
- 0.0 * stumbling_penalty # 惩罚绊脚(可选)
)
训练进度曲线(示意):
平均 Episode 奖励
高 │ ____
│ ___/
│ ___/
│ _____/
│ ____/
│ __________/
低 │_____________/
└───────────────────────────────────────────────► 训练步数
0 20M 50M 100M 200M 500M
↑ ↑ ↑
初期乱走 学会保持 步态稳定
直立平衡 可控行走
10.9 PPO 训练失败的常见原因与排查
现象 1:Loss 爆炸 / NaN
原因:学习率过大,或梯度爆炸
排查:检查梯度范数(应 < max_grad_norm),降低 lr,增大 clip_param
现象 2:训练后期奖励停止增加(平台期)
原因:熵太低(策略已收敛到局部最优)
排查:增大 ent_coef,检查策略的动作方差是否接近零
现象 3:训练初期奖励大幅波动
原因:优势估计不稳定,奖励函数设计有问题
排查:检查奖励缩放(reward normalization),检查 GAE λ 是否太大
现象 4:机器人在仿真中能走,真机上摔倒
原因:Sim-to-Real Gap(见第12章)
排查:加强域随机化,检查控制频率匹配,检查观测噪声处理
现象 5:策略进入周期性摔倒-重置循环
原因:Episode 设计问题(摔倒立即重置,没有足够的负奖励)
排查:调整 termination 条件,增加摔倒惩罚
10.10 PPO vs 其他算法的工程定位
为什么大多数机器人 RL 用 PPO(而不是 SAC、TD3)?
PPO 优势:
✓ On-Policy:训练稳定,调参相对容易
✓ 简单实现:没有 Replay Buffer,没有 Target Network 维护
✓ 大规模并行友好:直接 batch 推理,GPU 利用率高
✓ 自然的探索:Gaussian 策略 + 熵正则
PPO 劣势:
✗ 样本效率低:数据用完即丢(On-Policy)
✗ 需要大量并行环境补偿低样本效率
SAC 优势(第11章详述):
✓ Off-Policy:样本效率更高
✓ 最大熵框架:更好的探索
工程经验:有大规模 GPU 仿真时用 PPO,真机样本昂贵时用 SAC
10.11 PPO in Practice: 2025–2026 Developments
Since the original PPO paper (Schulman et al., 2017), the algorithm has become the undisputed workhorse of humanoid robot locomotion. Here are the most significant developments through early 2026.
Large-Scale Humanoid Deployments
Unitree G1 / H1 — Unitree’s open-platform robots have become the community standard for PPO-based locomotion research. By late 2024 and into 2025, teams worldwide demonstrated G1 walking on varied terrain, stair climbing, and recovery from pushes — all trained with PPO + domain randomization in IsaacLab. Key insight: curriculum on terrain difficulty (flat → slopes → stairs → outdoor) dramatically outperforms training on all terrain types simultaneously.
Figure AI (Figure 02, 2025) — Figure’s second-generation humanoid integrated a whole-body controller trained largely with PPO variants, enabling fluid loco-manipulation. The key architectural choice was asymmetric Actor-Critic: the Critic receives privileged simulation state (full body dynamics) while the Actor only sees onboard sensor observations — this closes the sim-to-real gap without explicit adaptation layers.
1X Technologies (Neo, 2025) — Demonstrated end-to-end locomotion-manipulation policies using a PPO-based framework with retargeted motion priors from human motion capture.
Refined PPO Hyperparameters for Humanoid RL (2025 Community Consensus)
| Hyperparameter | Typical Value (humanoid loco) | Notes |
|---|---|---|
| Clip ε | 0.2 | Standard; reduce to 0.1 for fine-tuning on real hardware |
| K epochs | 5–10 | More epochs → better sample efficiency but instability risk |
| Mini-batch size | 4096–16384 | Larger batches stabilize training with 4096+ parallel envs |
| GAE λ | 0.95–0.98 | Higher λ works well with long episodes |
| Discount γ | 0.99 | Standard; 0.995 for tasks requiring long-horizon planning |
| Entropy coeff c₂ | 0.001–0.01 | Critical for preventing premature determinism |
| Learning rate | 1e-4 to 3e-4 with cosine decay | Linear warmup for first 5% of training |
| Value loss coeff c₁ | 0.5–1.0 | Clipped value loss (PPO2) is now standard |
PPO Variants Gaining Traction (2024–2025)
PPO with Advantage Normalization per Mini-batch — Normalizing advantages within each mini-batch (not across the full rollout) significantly reduces variance from correlated environments in parallel training.
Recurrent PPO (RPPO) — Replacing the MLP Actor with an LSTM/GRU handles the partial observability of real robot sensors more robustly than frame stacking, at the cost of ~2× training time.
PPO + Reward Shaping from Motion Priors — Incorporating reference motion from MoCap data (via AMP-style discriminator or direct tracking loss) alongside the task reward enables more natural, energy-efficient gaits and is now considered best practice for bipedal locomotion.
本章小结
↓ TRPO → KL 约束步长 → 理论好但实现难
↓ PPO → 用 Clip 代替 KL 约束 → 简单高效
核心公式: L^CLIP = E[min(r_t·Â, clip(r_t, 1-ε, 1+ε)·Â)]
| r_t = π_θ(a | s) / π_{θ_old}(a | s) (概率比) |
实践要素: 数据归一化(obs/reward/advantage normalization) 梯度裁剪(max_grad_norm=0.5) 学习率调度(线性/余弦衰减) 多 Worker 并行(Isaac Lab:数千并行环境) ```
延伸阅读
- Schulman et al. (2017). Proximal Policy Optimization Algorithms. — PPO 原始论文 — arXiv:1707.06347
- Schulman et al. (2015). Trust Region Policy Optimization (TRPO). ICML — arXiv:1502.05477
- OpenAI Baselines PPO 实现:openai/baselines
- Stable-Baselines3 PPO(推荐):stable-baselines3 — 文档
- CleanRL PPO 极简实现:vwxyzjn/cleanrl — 单文件,极易理解
- Isaac Lab PPO 机器人训练:isaac-sim/IsaacLab
- Huang et al. (2022). The 37 Implementation Details of Proximal Policy Optimization — arXiv:2005.12729 — 强烈推荐,PPO 实现细节的权威指南